Week 4 : Dawn Of The AI
This week involved many things. We had a chance to interact with many ETC faculty during the 1/4 walkarounds. This was a great chance for us to showcase what we had accomplished to far and talk about our direction. We ran AI training multiple times with different model structures and hyperparameter values. Unfortunately, we could never achieve a win rate of more than 15.7% which means that we still have a lot of work to do towards the machine learning aspect of the project. Meanwhile, we also came up with a Unity frontend system for visualizing the gameplay and created a Django (python) website on localserver that gives designers a simple GUI to edit card values and even create new ones.
Feedback from Quarter Walkarounds
Here’s a list of some of the most important feedback we received:
- We need to come up with one or two metrics that we ‘target’. By targeting a metric, we want to measure the impact of making game balance updates on these metrics. For example, one of the metrics that we are leaning towards is win rate. By focusing on win rate, we can put game balance changes in perspective to judge whats good and whats not.
- We need to reach out people in the reinforcement learning space who can help us out with the AI part. Since this space is technically challenging and it is is still quite unexplored, it would be a good idea to get in touch with someone more experienced in the space.
- We need to create an organized system that can help game designers interact with the AI. This can be to help with inference from general statistics by creating data visualizations or even an interface to train the AI after making game design updates.
- We need to write a paper as our final deliverable. This makes sense because what we are doing is highly exploratory. A good to extract value from the work that we have done is to document it all for people who may want to work in the same space after us.
AI Training Experiments
This week involved a lot of AI training experiments. In all honesty, none of our experiments were successful. The highest win rate that we ever got was 15.7% and that is not very good. However, it is still a little better than a random bot. There were two models that we implemented this week:
Model 1 : Single Model With All Input Data
This is a single model that takes in all of the state input at the same time. This results in 98 input neurons that look like the following:
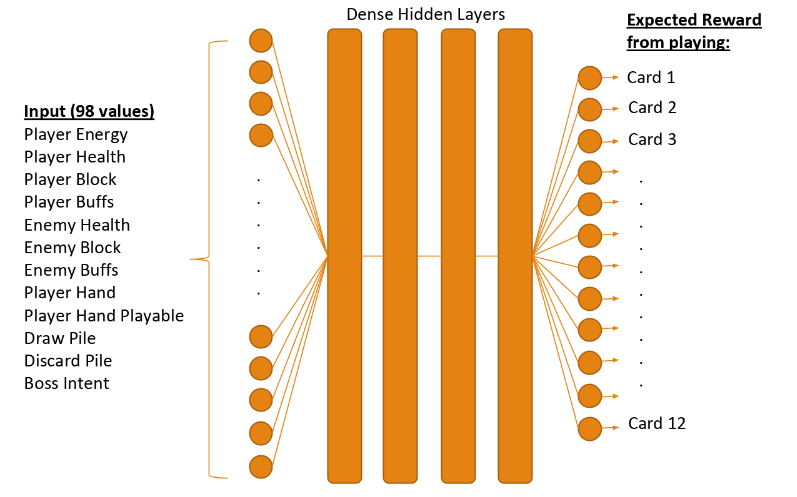
The output consists of estimated Q-values for each card. The neural network is setup to estimate the expected reward values from playing each card given a particular state. The AI agent will then go ahead and play the playable card with the highest Q-value. This does not always mean that the card with highest Q-value gets played since it might not be possible to play that card (player energy, card not in hand, etc).
There were several issues with this model that we had to iron out as we ran training. For one, the estimated Q-values were getting very large and would eventually resulted in a Nan error. This was rectified by changing the activation function of the middle layers to sigmoid instead of relu. We also tried regularization as a way to handle this but that resulted in the estimated Q-values being too small.
All in all, we got the model to work but it did not show any improvement in the average reward over the duration of the training. Perhaps, it is difficult for the AI to infer insights from the data because too much of it is being presented at once inconsistently.
Model 2 : Multiple Small Models Each Predicting Independently
The other model we implemented involved getting rid of a single big model but instead making multiple small models. For the sake of experimentation, we created three smaller models as follows:
- Buff Model – Consists of 7 input neurons, each indicating whether a certain buff is present on the player (or boss).
- Cards Model – Consists of 13 input neurons indicating which cards are in the players hand. One additional neuron to indicate player’s energy level.
- Boss Intent Model – Consists of 7 inputs neurons, indicating what is boss’s intent. Out of the 98 values that indicate the game’s current state in model 1, here we are only taking 7 + 13 + 7 of them. By filtering out some of the information, we are losing out out on the AI’s knowledge of the state space but at the same time we want to try this out to see if the AI does any better.
By taking a weighted average of the independent Q-values predicted by these three smaller models, we were able to get a win rate of 15.7% which is higher than the random bot. This is good news, because we know that we are doing in the right direction.
However, with that being said, the performance is still quite bad. We are now looking to implementing a more complex and fine-tuned reward function that could potentially help with improvement of training. If that too does not prove to be helpful, we shall look towards policy gradient algorithms to try and solve this problem with a fresh approach.
Unity Visualization
We made some progress on our quest to create a Unity visualization of the game. In the last week (Week 3) we had implemented a python version of the game ‘Slay the Spire’ which involved a single boss fight against the level 1 boss ‘The Guardian’. For starters, we worked towards implementing a UI for playing the game which looks like the below.
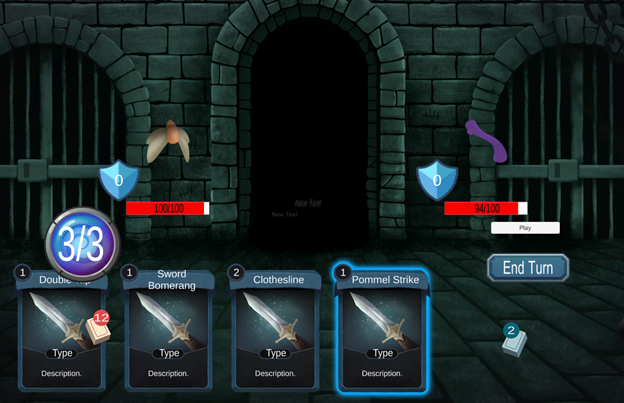
The following are some key features of the Unity system:
- Decoupled Front End : Front-end includes all animations, UI, and graphics, but does not have any control over the gameplay logic.
- Data Driven Rendering : Rendering of the game is based on data, just like browsers render HTML. So when we change game logic in python, the rendering part would change according to the data sent back from python. This ensures that we dont need to modify the python code too much.
- Art Resources Hot Update : Art-side resources shouldn’t be embedded in the application. All of them are configurable and can be hot updated. Art assets can also be provided as tools (for the game designer) and results can be immediately seen without restarting the application.
- Playback System and Debugger : Support for a playback system based on log data. This is to see how AI plays the game by visualizing its moves.
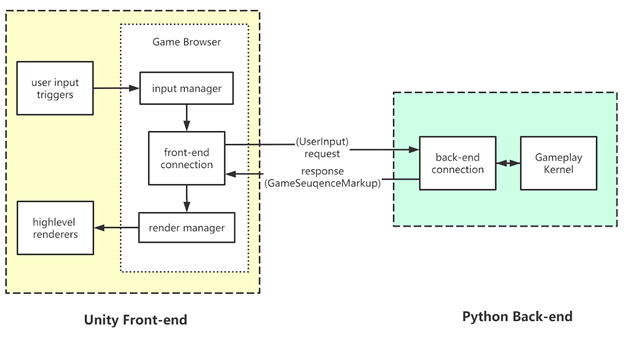
The implementation of the Unity Visualization system follows a front-end/back-end architecture. This is largely inspired from the modern web stack: HTML/Browser/CSS/JS because we have a similar situation. Instead of a game application, Unity is simply a renderer along with some input management. It renders the information from the python module, and gathers user input to send back to python. It is very similar to the relationship between browser and server. The following is a diagram of how this architecture looks:
Web GUI for Card Modifications
An important piece of our project is to make our system more friendly for game designers. To that end, we began work towards a web GUI for editing the json card files. The idea behind this system is to let the users modify existing cards or create new cards. This system uses a Django backend that is hosted on localserver for editing the card files locally. The following is a screenshot of how this looks right now:
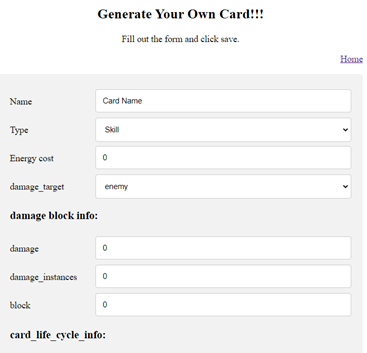
The fields in the image are from the card json files. These are all values that would need to be edited by opening up the json file. Instead, this system can also be used to make similar changes.
In conclusion, this week involved progress on multiple fronts. However, the biggest concern right now is that the AI is not performing well. In the coming week, more of our efforts will likely be to push towards success in this area.