Week 6 : A Small Breakthrough
This week saw more work along similar lines as the last week. One major improvement for the AI came as a result of making it simpler for our designer to run training. A major algorithm update was also done which helped us improve training results. A whole set of new cards was added to the game for which we had to add some additional reward functions. Training data is now recorded better with a lot of important statistical information and charts being saved in an excel file. On the Unity front, we finally finished the GUI prototype of the boss fight based in Unity. We sent it out to our faculty instructors Mike Christel and Scott Stevens to test. Finally, we also began preparation for halves which is due on 19th October.
AI Updates
The updates made to the AI can be broken down into the following three parts:
Flexible State and Action Spaces Flexible state and action spaces implies that the AI Agent script no longer needs explicit instructions about the state and action space. Instead it picks up this information from JSON files just like other parts of our app.
State Space : The state space is constructed by looking at the state space selector file. This is a JSON file that has a bool value attributed with various portions of the state space (player buffs, boss intent, in hand cards, etc.). Before starting training, you can now directly modify this file to choose what should and should not be included in the state space for AI training. The below is what this looks like right now:
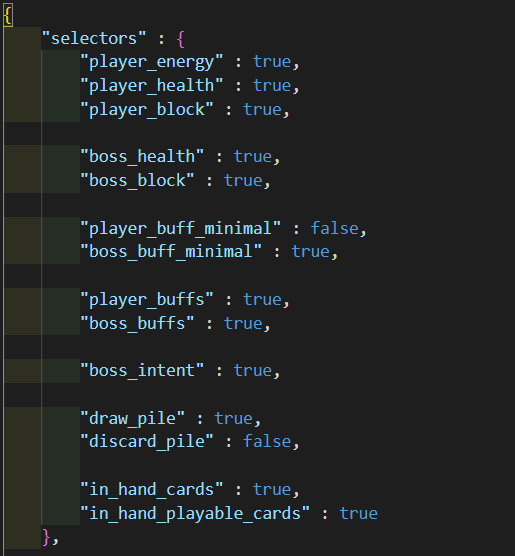
Action Space : Constructing the action space involved looking into the database module and getting information about the current deck configuration. The action space is then constructed by adding a neuron for each card which has a non-zero count in the deck. There is no input required to directly modify the action space.
The reason for adding this feature is to make it much simpler for a designer to run training. Now the designer simply needs to choose cards to add to their deck and update the state space for including states that they want in the state space. This format is also great to integrate with a GUI system that can make doing the above as simple as filling out a form containing different elements of the game state.
We needed a system like this to make the AI training more accessible to our designer. There are still many experiments that need to be run and many of them involve modifying the deck and updating the state/action space.
AI Algorithm Updates
Another important task this week was the modifications made to the A-Learning algorithm. Last week, the major change we made which resulted in stable learning was updating the discounting factor (gamma) to zero when calculating a state’s expected reward. This essentially meant that expected reward of a state is equal to only the immediate reward received from the current state. The reason learning becomes stable by implementing this is that the q-target becomes fixed. Earlier (with gamma > 0), the q-target value for the same state could change as a result of updates made to the q-learning model. But if the discounting factor is made zero, the q-target becomes exactly equal to the immediate reward (the reward is stochastic in our environment as a result of the game’s randomness).
This was what we did last week. This week, we wanted to increase gamma to be greater than zero while still ensuring that training remains stable. We did this by adding another model to the AI Agent script. Thus essentially now we have two models. The setting is such that one model is used only for prediction and the other model is used only for training. When the model being trained has gone through enough iterations, the model making predictions is deleted an the trained model takes it place. A fresh model is instantiated to be the new training model. A shorter version of the same is outlined below.
- Instantiate two models Q-Train and Q-Predict
- For number of games:
- Q-Train is initially trained while Q-Predict is used to make predictions (the first Q-Predict model will only make random predictions)
- If Q-Train has gone through enough iterations:
- Q-Predict = Q-Train
- Q-Train = new model
Essentially, the purpose this serves is that it keeps the q-targets stationary for a length of time while the Q-Train model is being trained. This stabilizes the training of the Q-Train model. Once the Q-Train model is ‘experienced enough’, it can start making predictions.
Another thing this enables us to do is to make gamma > 0. But this is not done immediately. Instead, the starting gamma is 0 but every time the Q-model is switched, the gamma is made a little higher. Hence, the discounting factor starts off with 0 and increases by 0.2 every time the Q-model makes a switch. This way, every fresh Q-Train model, attributes a little higher weight to the future reward as well as the expected reward.
Implementing the above algorithm update has increase the win rate from 0.4% to 7.87%. Although the win rate is still far from good, the AI is definitely performing better and has started winning in a setting that is challenging even for a human (player hp : 75, boss hp : 240). This is the biggest breakthrough at AI training that we have had in a while. As a result, it gives us hope that we are on the right path for making progress towards the goal.
Reward Function Updates
The last piece of AI updates involves updates made to the reward function. There were bugs in the reward function that resulted in unfairly high rewards to the damage dealing cards. This has been modified and rewards to the buff cards and block cards has been buffed a little. Using a complex reward function like this is something that we want to move away from in the long run. The idea behind reinforcement learning is to train the AI as much as possible with only rewards for achieving goals. What we have ended up doing is giving a lot of intermediary goals to push the AI towards achieving the desired goal. The reason is simply that we have not had much success with rewards only for the final goal and hence we introduced intermediary rewards. However, this is something we would like to change.
AI Training Statistics
Another significant improvement made in the previous week is the addition of comprehensive AI training statistics as a part of the AI generated data. To do this we had to add many new scripts that deal solely with collecting, processing and writing AI training data.
The generated statistics file is now a .xlsx file which includes two worksheets.
- Training Data : This worksheet provides episode details of each game played by the AI. This includes the following information for each episode:
- Episode Number
- Epsilon value for that episode
- Total cards played in the game (each episode is one game)
- Total reward for this episode
- Win/Loss
- HP of the Boss at the end of the game
- HP of the Player at the end of the game
- Max Damage done in any turn of the game
- Average damage done in the turns of the game
- Episode indexes when model was switched
- A graph showing a rolling average of total episode reward (average over 20 games including the current and following 19)
- Card Statistics : This worksheet provides insights into the performance of each card in all games played during training. This includes the following information for each card in the deck:
- Action number (this is the number of the action neuron representing the action of playing this card)
- Card name
- Count of this card in the deck
- Card play count : times this card was played in all games of training
- Opportunities of playing a card utilized. It is a ratio of how many times a card was played divided the number of times it was available
- Average card play position. At what step in the turn was this card played on average. For example, if a card was always played between the first in all turns, its average card play position would be 1.
- Average reward obtained by playing this card.
- Graphs of Card Play Count, Card Play Opportunities Utilized and Card Average Reward
Below are screenshots of these excel sheets and what they look like right now:
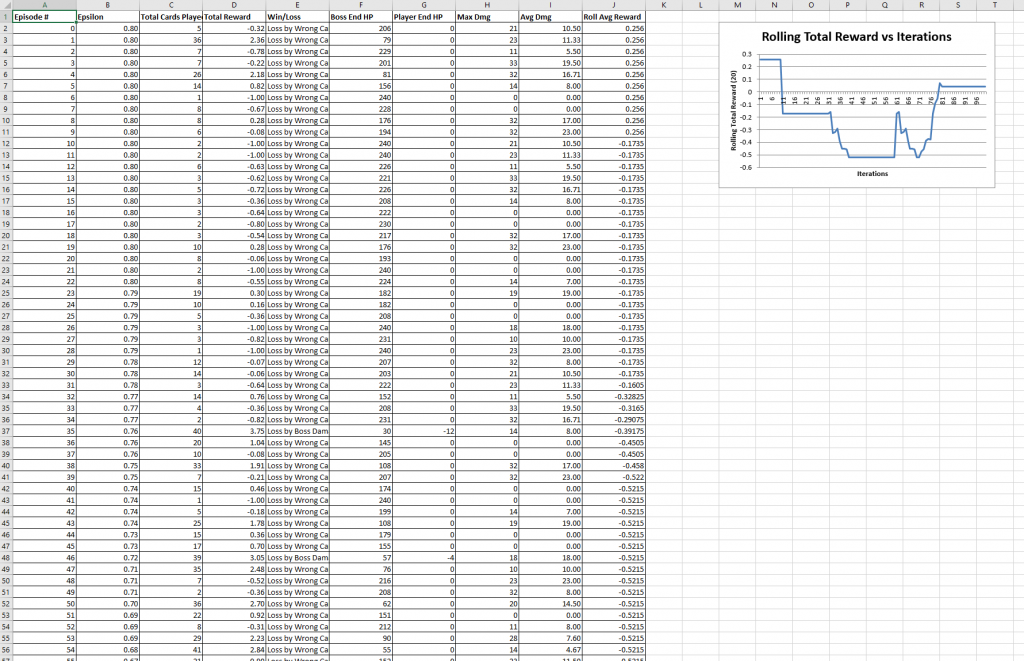 Training Data Worksheet
Training Data Worksheet
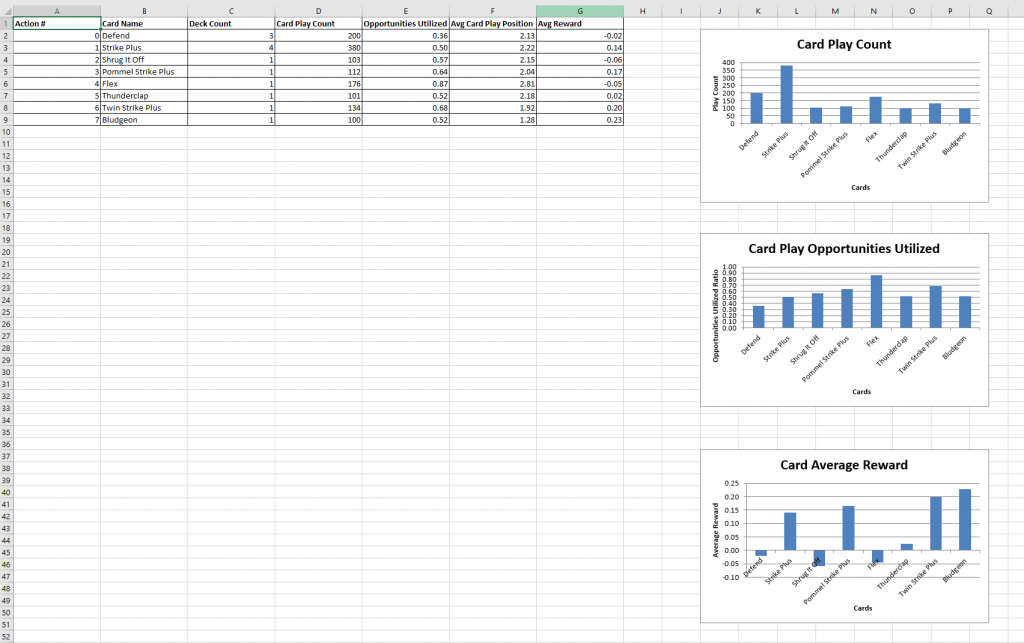 Card Statistics Worksheet
Card Statistics Worksheet
These statistics have already given us some great insights into what is happening during training and how the AI is thinking while playing cards. Although this is not an exhaustive list of the statistics we wish to provide the game designer, it is a start towards achieving the greater of training the AI, i.e helping the designer. As the AI training improves, these statistics may prove to be quite valuable to the game designer in making game design decisions.
Python Integration Into Unity Build
As a result of the game backend being in python and rendering of graphics in Unity, in the past we had two separate applications running at the same time. We figured out how Unity and Python communicate, however, this only works during development. Once we build the project and deliver it to players, it becomes more complicated because unity manages its own resources and builds most of them into binaries or machine code. To figure out how to do this, we analyzed some of the various options available to us.
Option 1 – Remote Server:
Python code will not run in the build, instead it will run on a remote server. This is doable to some extent, because we use sockets to communicate between Unity and Python. And our architecture is very similar to a frontend-backend model.
- Pros:
- Needs very little work, just run python on another computer as a server when playtesting.
- More convenient to collect data from playtesters in the background.
- Cons:
- The build is not self-contained. Always needs remote server to work.
Option 2 – Integrate Python Executable into Build
Use tools like pyinstaller to pack python code into a .exe, and then start that .exe when Unity application starts.
- Pros:
- The build is 100% standalone.
- Cons:
- Build fails in our project now, using pyinstaller. We need time to make sure the build process works.
- We wrote our database module in Python. We don’t want to put data (images, configurations) into the python executable directory.
Option 3 – Interpret raw python code files within build
We make a unity build first, and then include python code directories into Unity build. During runtime, the Unity application finds the Python interpreter to execute the code.
- Pros:
- The process is 100% transparent. We have full control of the directory, resources and data in the build.
- Cons:
- Not 100% standalone for now. There is a dependency on the python environment in the user’s computer.
Final Decision : (3) Include raw python code files within Build
We don’t want to maintain a server which eliminates option 1.
Option 2 would be ideal if it works, however, pyinstaller is a big unknown to us and we don’t know how much time we need to fix it
We made option 3 work, and in the future we plan to install the required environment for users before starting the application.
Playable GUI Version of Game
In week 4, we designed and implemented the architecture of combining gameplay in python and GUI in Unity.
In week 5, we developed the animation workflow from python to unity.
Finally during week 6, having the existing foundation, we made our first playable version! Below is screenshot of how it looks:
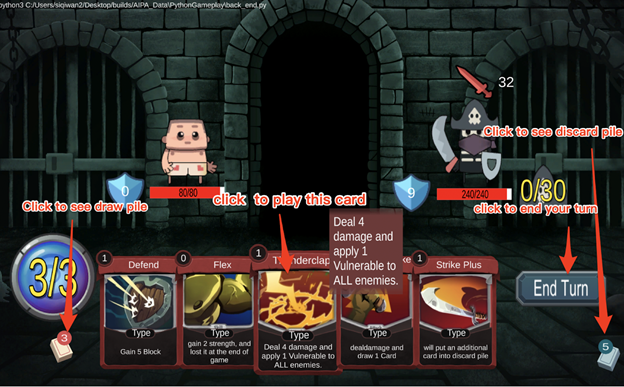
A lot of work went into making this run. Here are some key highlights of the steps we needed to take:
Enriching the C#/Python protocol
Previously, our protocol only supported requests of user input and response of markup files for unity to render.
Now our protocol supports multiple types like system error, game life cycle update, etc. Additionally, it is also extensible for new types.
Resources (card image/tooltip text) management from python database to unity
Now we can configure the images, descriptions of cards in the database (python). Unity will read this data according to the configuration!
Information display
Card information, deck information, description and images of every card, states and information of player and enemies, are all showed to the player.
Comprehensive and robust Main gameplay process
From connecting to backend, start game, player turn, enemy turn, loss/win and replay. We now have a complete process for playing, recording and replaying the game
Input validation
The previous version allowed the player to freely click all buttons and send requests to the backend, but these inputs were not validated in the backend. For example, validating if the card played is on your hand or if you have sufficient energy to play it. We recently added input validation to make the application robust.
Addition of New Cards
In the last week, we added several new cards to the deck. These have been integrated such that they work in the game as well as for training AI. The new cards include a lot of the ‘plus’ version of our existing cards as well as some newer cards. A list of the new cards is below:
Plus versions of existing cards:
- Anger Plus
- Body Slam Plus
- Clothesline Plus
- Defend Plus
- Disarm Plus
- Flex Plus
- Heavy Blade Plus
- Pommel Strike Plus
- Sword Boomerang Plus
- Shrug It Off Plus
- Iron Wave Plus
The new cards that have been added are:
- Bash / Bash Plus
- Bludgeon / Bludgeon Plus
- Thunderclap / Thunderclap Plus
- Twin Strike / Twin Strike Plus
- Uppercut / Uppercut Plus
Adding these new cards inches our implementation closer to the real version of Slay the Spire (it is still quite different). It also gives our designer the ability of modify the deck with many different cards and running training with various different deck versions.
All in all, we made a lot of significant progress this week. We are excited to show our work at halves and for the future of our project!