Week 1 : Getting Started
The objective of our project is to create an AI that can playtest card games and help balance it. We expect that the AI will identify dominant strategies to win the game, and this can lead us to making game design updates to the game. To do this, we are going to design our own card game because we want flexibility over the rules of the game. We want to test our AI with different game mechanics to see what problems (in the context of card game mechanics) it can solve easily and where it struggles.
We plan to use Python to build our game kernel and have some communication with Unity for visualization of game play.
For our project to work successful, we have divided it up into multiple aspects – the core game kernel, the AI, communication with Unity and game design for the card game. We need to work towards implementing each of these and ensure that they work well together.
Game-AI-Input System
The following is a simple representation of our system that implements the above.
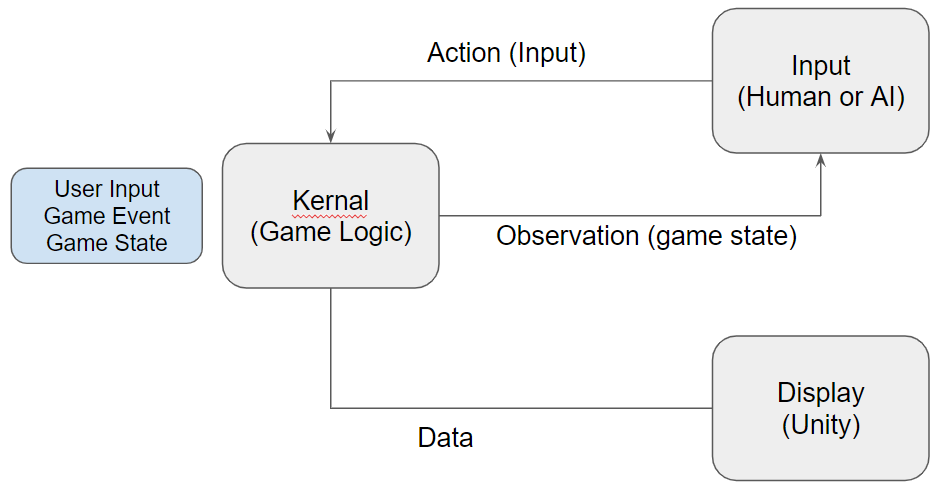
Here are the requirements from this system:
- All the gameplay logic executed in a module called”gameplayKernel”
- Other modules are only able to provide userInput and get what gameState and triggered gameEvents after this input. Exactly how game logic is executed is 100% invisible to them.
- All the gamedata is separated into a structure call game state.
- Game kernel is 100% decoupled with graphics/UI and AI training
In the first week, our objective was to come up with a playable Rock-Paper-Scissor-Dragon card game and then train an AI agent to play it. RPSD is our take on the classic (and balanced) Rock-Paper-Scissor game with the exception that there is a Dragon action that defeats rock, paper and scissors but draws to another Dragon. The idea behind doing this is to prove that in the simplest of settings, the AI agent can identify the obviously broken part of the game.
Unity – Python Connection
Research on the ways to achieve this:
- To have a python interpreter in .NET environment (https://ironpython.net/) . The cons is this is not stable, and will have some trouble when using external python packages like numpy.
- Use command line to execute the python program, and redirect the standard input/output from cmd to C#/Unity environment. This is doable, but using standard input/output to communicate is inconvenience. And this need player to install the python environment
- Python programs run in another process, and Unity in another process. Use socket to transfer the information between to language. This is what we finally chose, but it still needs more work. We need to think about how to call a function and share object instances.
AI Agent
Since the AI problem is so simple, we implemented followed a simple tabular reinforcement learning approach. To elaborate, we maintain a table of the expected reward from taking each of the four actions (rock, paper, scissor or dragon). We update these expected reward values based on the rewards from each game. The agent uses an epsilon-greedy approach with a constant epsilon value of 0.1.
Since the dragon will naturally has the highest chance of winning any game, over a period of time the expected reward for a dragon is the highest. Here are some charts of the training results.
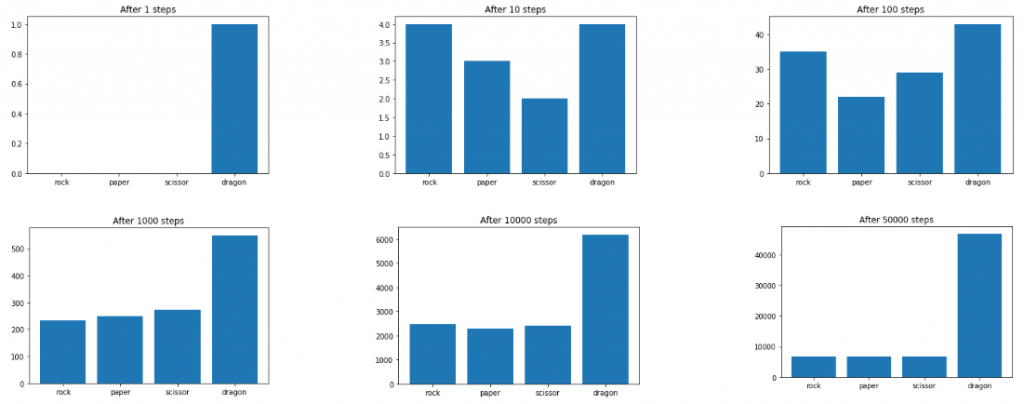
Each plot shows the number of times the AI agent picked each action. We see that after 100,000 steps, the AI agent predominantly picks the dragon action. The minority of actions that are not dragon can be attributed to the epsilon probability value.
Although, this worked, we are well aware that this problem is trivial compared to building an AI to play a complex card game. Since the action and state space can be very large, a tabular reinforcement learning approach can no longer work. In this situation, we need to use a neural network to estimate expected reward. The input layer can be a vector of integer values that represent the current state space. The output layer is more tricky because it involves a fairly complex action selection.
Game Design
Last but not the least, we arrive at the game design component of our project. We plan to have a game that starts with a simple rules and few mechanics but eventually evolves into something more complex. This can help with us progressively increase the reinforcement learning model complexity.
The first version of the game only involves two systems:
- Hero system
- Card system
The hero system consists of two set of actions to choose from. Player has to decide the positioning of each hero in each round, because normally a hero can only attack the enemy that is in front of it. Additionally, each hero will have two extra skills that require a particular resource to unlock, which is the second set of actions that needs decision making.
The card system also requires players to make decisions between short long term rewards. The player may choose to deal maximum damage each turn, or choose to gain resources to level up and fight back. Ideally, we want a variety of different strategies to be viable
The game, of course, requires large amounts of balancing. For example, the HP and attack damage of each hero, the amount of resources that are required to level up a skill, and the drawing probabilities of each card are all crucial to this game being balanced. This is where we hope the AI can help us out.
In conclusion, we believe we have had a strong start to the project. Our objectives that we need to achieve are clear. We want to explore relatively unexplored territory that is technically very challenging. All we know for certain is that we are excited!