Week 7 : A Little Bit of Success
This was the week before halves and all of us spent a considerable amount of effort in preparing for it. However, we also made some considerable progress in both the AI training as well as the Unity visualizer. Most importantly, we managed to improve the AI’s winrate to ~60% which is significantly higher than the previous week’s ~13%. This came as a result of several bug fixes, addition of a new input feature and a modification while calculating q-target values. As part of the Unity visualizer, we can now integrate a trained AI with it to see how the AI predict’s expected rewards from playing cards in a turn. Along with this, we also implemented a state editor tool which allows us to create our own states within Unity that can be very useful in seeing the AI’s reactions in particular states. Lets go over each of these one by one.
AI Algorithm Updates
The list of things we tried and tested this week are as follows:
Addition of ‘Remaining Damage for Boss Mode Change’ as an Input Feature
The Guadian (boss in our implementation) in Slay the Spire has two distinct modes offensive and defensive. It also has specific intents for each phase. When the Guardian is in offensive mode, it generally deals a higher damage than when it is in defensive mode. The switch from offensive to defensive modes happens as a result of damage from the player and generally this is a tool for the player to force the boss into the stance which is favorable to the player.
This feature had been left out in our initial models which could have been one of the contributing factors to why the AI was performing poorly. Luckily our faculty instructor Mike Christel pointed this out during one of our faculty meetings where he saw the state space and found this value missing. Addition of this feature to our state space did not immediately result in improved results, however we believe that it was a contributing factor that propelled the winrate higher.
Action Masking
An approach we focused on this week came as a suggestion from a conversation with a PhD student on main campus James Cunningham. As another strategy to teach the agent about unplayable cards quickly, we decided not only to adjust the q-value of the card that was played but also to adjust the q-values of all the unplayable cards. How do we calculate the target q-values for unplayable cards? Well, since these cards are unplayable we should give them the same negative reward that we give the agent when it tried to play an unplayable card.
This means that there would be a negative reward associated with all unplayable cards while constructing the q-target vector only the playable cards could have positive values. Since the largest negative reward is for trying to play unplayable cards and losing, the agent is motivated to quickly learn which cards are unplayable. Earlier, we saw that the agent generally took ~1000-2000 games to learn to not play unplayable cards. With action masking implemented, it now takes ~200-300 to learn to not play unplayable cards. This is a big leap and it gives the agent more time to learn and explore the actual game.
Testing different values for Number of Iterations before Q-models switch
Last week we introduced the idea of using incremental gamma values along with 2 q-models for our training process. This week we tried an experiment to check what is a good number of iterations for the q-train model to train for before we make the q-model switch.
We tested with 10,000 iterations before switching and this resulted in a very poor winrate of ~10%. This is significantly lower than the ~55% winrate that we got with 100,000+ iterations. We also tested with 500,000 iterations and this also gave us a winrate of ~60% implying that increasing the number of iterations too much does not improve the winrate considerably.
Ideation towards our Playable Prototype
One of our deliverables for the project is to create a playable prototype that is accessible for designers, can run AI trainings and can also provide an interface to load up the Unity visualizer.
Our current plan is to have a home page which is similar to a central hub that controls everything else. This would contain paths to the following:
- Create & edit cards page: enable designers to create and edit cards.
- Deck building page: configure what and how many cards to include in a version of the deck.
- Modify AI training parameters page: set hyperparameters like gamma (discounting factor when calculating rewards/q-value), epsilon (whether choose random action), number of iterations, etc.
- Modify state/action space page: modify the state space (player hp, boss hp, cards on hands…) and action space (possible cards) for the AI training process
- Train button: run the training process along with a progress bar to indicate how much of training is complete.
- Unity game visualizer: for manual playtesting and visualizing AI decision making after AI training is complete.
- Statistics Sheets: after training is complete, user can see an excel sheet that give insights about training performance and AI decision making with respect to the cards in deck.
Here is a screenshot of one of the slides for our halves presentation that shows these different components in actions:

Integration of AI into Unity GUI
An important milestone for our project was the integration of AI into the Unity GUI. This is a big thing for us because now we can finally visualize how the AI sees the cards in any particular state. Below is a screenshot of how this looks right now:
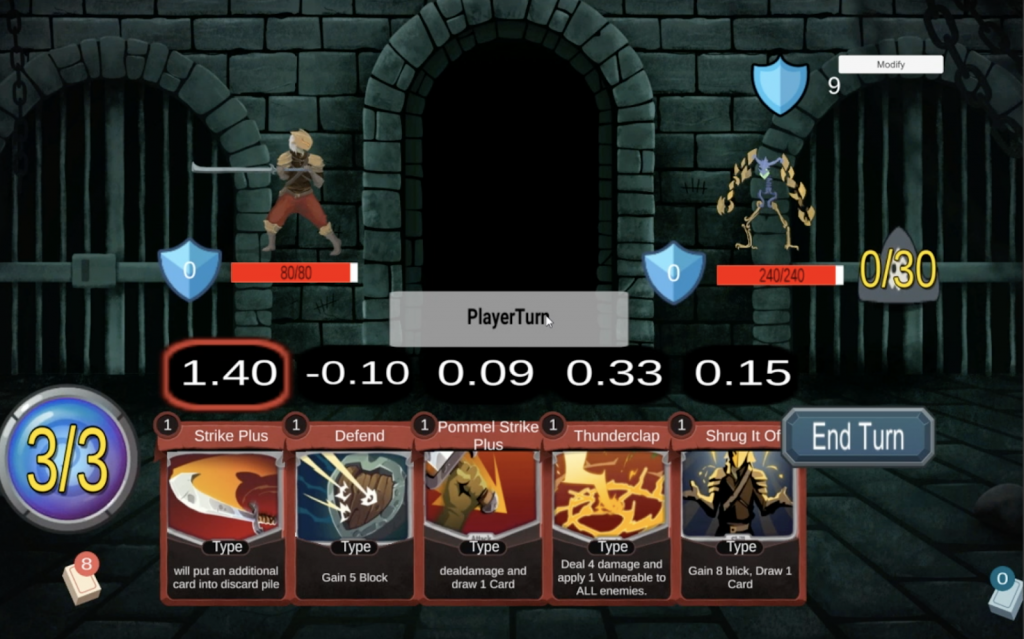
The values seen above the cards in the picture above are the expected rewards for playing each card as predicted by the AI. The highest value (in the example above this is Strike Plus) is highlighted to show that this is the card recommended by the AI. If the AI was playing the game, it would always play the highlighted card.
Backend integration
The system currently works only after the AI has been trained completely. Backend provides the current gamestate to the AI Module, and then gets rewards for each card. Because all projects(AI/Gameplay/Unity GUI) share the same definition of ‘game state’, this part is simple.
Frontend integration
As we discussed in previous weeks, frontend is designed to work in a ‘data-driven’ render mode. It works like a browser; backend gives markups of game state and game event to frontend, and frontend parses the information to render the GUI.
So in the frontend, showing reward values is just adding another type of markup. Our markup system and existing rendering workflow is designed to be very flexible with these kind of changes.
Runtime Game State Modifier
This week we also implemented a runtime game state modifier to allow us modify game data when the game is running. This serves as a tool for programmers to create test cases to test the AI’s decision making. It can also be used by designers to craft scenarios in order to see how the AI interprets certain cards. Here is a screenshot of how this looks right now:
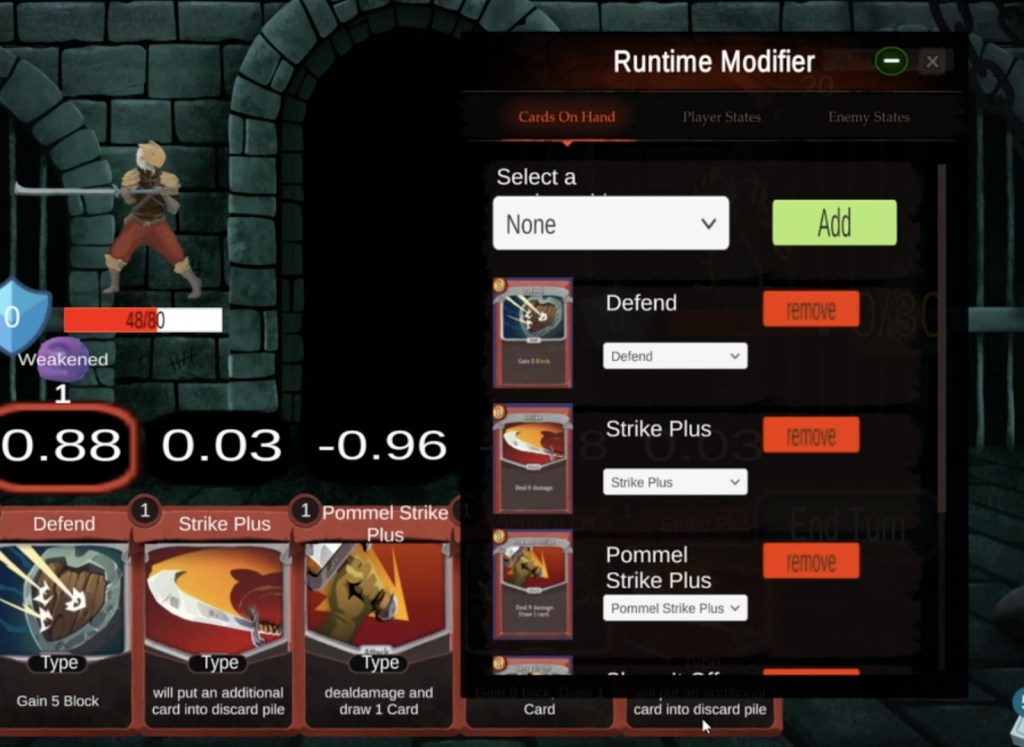
Runtime modifier program design
When we consider a runtime modifier, we mainly consider 3 things;
- Flexible/Self-adaptive: We need to modify the gamestate, which keeps changing throughout the development process. The ideal case is this modifier adapts with newer versions of gamestates and we don’t need to rewrite any part of the code.
- Instant feedback: This is the reason why we want to integrate this in runtime. Because gamestate modifications may happen with a very high frequency (especially when you have a value slider, it will change multiples time in one second). If it reloads the whole game ,which is more than 30 seconds, it would be a very frustrating experience.
- Undo/redo support: This is a basic requirement of any effective and efficient tool!
Approach 1- Incremental modification:
A possible design for this is that it works like a version control software like git. We use increments to present each modification and apply these increments to the gamestate.
- Pros:
- Instant feedback and very efficient. We can even let modifications happen immediately in the local GUI and then let the backend validate.
- Cons:
- Not flexible: we need to write codes for every kind of modification, add/remove/change for all types of data in the gamestate.
- Undo/redo problem: it is doable, but will take a lot of work. Whenever we write an ‘Apply()’ function, we also need to write a ‘Revert()’ function.
Approach 2-Snapshot-style modification
This is the design we settled on. Whenever modifications happen, it will trigger Frontend, take a snapshot of the current gamestate, and then send back to the python backend to overwrite the current gamestate with the snapshot.
- Pros:
- Self-adaptive: We already had gamestate markups encoded by backend, we just modify the markup and send it back to python. Because all encode/decode happens in python, which is a dynamic language. Hence, all changes can be self-adaptive.
- Easy undo/redo support: We will do this in future. But if it just saves the snapshots in buffer, this will not be too hard.
- Cons:
- Instant feedback: this might be a problem in other games, when you want to take a snapshot of the whole game. For now, a snapshot of our game is less than 4000 Bytes, so it is acceptable.
Parallel Frontend-Backend Communication
In order to better support the runtime modifier, we modified our frontend-backend communication to go from ordered single sequence into multiple parallel sequences.
Previous ordered single sequence:
In the early stage, the scenario is very simple. GUI sends user input as a request, and python sends markups or system errors as response. The request/response mainloop just follows the gameplay: playerturn, playcard, enemyturn and enemy intent.
Current parallel multiple sequence:
Now GUI sends more requests than just the player input. It also requests database queries and runtime modifications. In the single sequence model, if the mainloop expects a player input, but receive a database query, it’s very difficult to handle.
Now the backend has independent mainloops for gameplay, database queries and runtime modifications. We largely refactored the backend and gameplay code to make this change.
Halves Presentation
All the above mention progress aside, we were also working on our halves presentation. This is going to be a good opportunity for us to show the ETC faculty about what we have been doing and our journey to achieve the results that we have.
Our presentation is on Monday (19-Oct-20) at 4pm and we are looking forward to it. As it turns out, we will be the first team doing halves presentation this semester. We hope to do a good job!